While exploring options for executing complex workflows that contain multiple tasks, we came across Airflow. It proved to be a game-changer for us by effectively boosting the scalability of our machine learning pipelines. Moreover, Airflow is an open-source tool that has strong community support and widespread adoption among various organizations.
In the following blog, we will explore three different ways to execute workflows in Airflow. These methods can later be transformed into complex pipelines based on the requirements of your environment.

In our analysis, we will present the comparison we conducted for each workflow. It’s important to note that there are also numerous alternative approaches for executing your workload.
We will execute a simple workload using each of the following components:
- CeleryExecutor
- KubernetesPodOperator
- AwsBatchOperator
An Overview of Our Infrastructure Configuration
Before we delve into the examples, let’s visualize the layout of our infrastructure and provide a couple of guidelines on how to launch it.
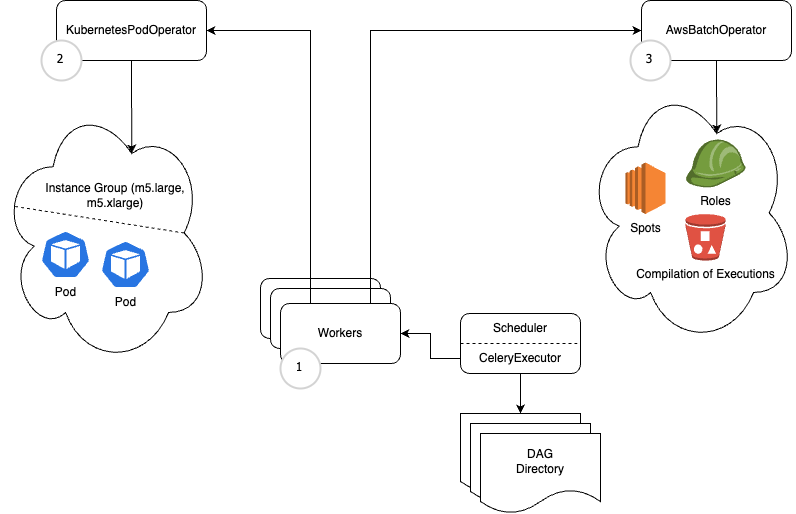
Looking for instructions on how to install Airflow on your Kubernetes cluster, you can refer to the following Quickstart Guide.
Analysis of the Celery Executor
We have chosen to use the Celery Executor in our workload as it provides faster execution and it is ideal for us to manage short and moderately complex tasks where immediate output is crucial for making decisions in. the pipeline logic. However, for computationally intensive or time-consuming tasks, we will choose a different executor to ensure efficient processing.
This DAG contains 500 parallel tasks that are running on 3 workers. When we executed it, we were able to achieve an average runtime of 3:24 minutes.

It is important to emphasize that resource allocation is a key factor in this matter. Increasing the number of workers can indeed lead to improve results. However, I prefer to avoid the complexities and scalability concerns that comes with managing additional workers. Instead, I opt for running my workload on isolated machines. There are multiple reasons for this preference, one of which is to prevent a single worker’s failure from impacting the remaining tasks. Even though the scheduler attempts to trigger them again, a worker crash can disrupt the execution of the remaining tasks within the DAG. Therefore, I have decided to transition to use the Kubernetes pod operator, which enable me to run my workload in dedicated pods.
The reference code can be found here.
Analysis of the Kubernetes Pod Operator
Setting up the Kubernetes pod operator was a straightforward process for me. I simply followed the Airflow documentation and implemented it in my environment. As a result, I experienced significant improvements in both speed and reliability. I no longer encountered any worker crashes, thanks to the dedicated instance group where all my workloads were running.
Despite implementing the Kubernetes pod operator, my main bottleneck still lies with the workers because they responsible for scheduling tasks to run. While the specific task in my example may not be complex, the overall improvement in runtime is relatively small. However, in a more intricate environment, the use of the Kubernetes pod operator would likely lead to a significant improvement in performance.
When executing this DAG, we launched 10 instances to handle the execution of its 500 parallel tasks on a Kubernetes pods. As a result, we achieved an average runtime of 2:02 minutes.

Similar to the insights gained from the Celery Executor, we identified the potential to allocate additional instances in our Kubernetes cluster to handle more complex workloads. However, considering various factors such as cost, we decided not to push our Kubernetes cluster to its limits. As a result, we made the decision to switch to use the AWS Batch Operator.
The reference code can be found here.
Analysis of the AWS Batch Operator
As our infrastructure continued to expand exponentially, we recognized the need for a cost-effective, manageable, and scalable solution to handle our increasing workload. Consequently, we made the decision to leverage the AWS Batch Operator and direct all tasks to run on the cloud service. This approach allowed us to offload heavy workloads from Airflow, which improved our pipeline and also reduced our overall costs.
When we executed the following DAG, we configured the compute environment to support up to 3000 CPUs using a combination of machine types such as: c5.2xlarge, r4.2xlarge, and m5.2xlarge on AWS Batch. This setup efficiently handled the execution of the 500 parallel tasks, resulting in an impressive average runtime of 20 seconds.

So far, we are extremely satisfied with the scalability we have achieved by combining AWS Batch with the Kubernetes pod operator. This powerful combination has significantly enhanced the overall performance of our infrastructure.
The reference code can be found here.
Maximize Your AWS Batch Operator
To enhance task diversity with AWS Batch, we will introduce a new approach. We created a file called tasks.txt where each line represents a unique command. This file is then uploaded to an AWS S3 bucket. When the DAG started, it automatically downloads the tasks.txt file and determines the amount of the tasks in AWS Batch based on the number of lines in the file.
Let’s try it:
- Create a bucket in AWS S3
- Download and Upload the tasks.txt to the AWS S3
- Upload the DAG to your environment and remember to modify the bucket name within the DAG.
Once you review the AWS Batch Job, you will notice that it has generated 6 tasks according to the number of lines in the tasks.txt file. By examining the logs of each task, you will notice the corresponding output.
The reference code can be found here.
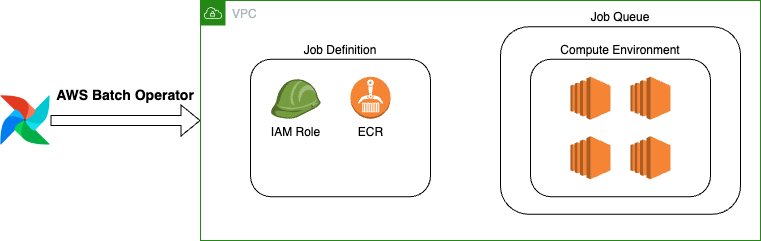
Setting Up Your AWS Batch
Before using the AWS Batch Operator, you must first create the following components:
- Amazon EC2 spot fleet roles
- ECS instance role
- Batch service IAM role
- Compute environment
- Amazon EC2 job queue
- Job definition on Amazon EC2 resources
Summarize
In this article, we explored three approaches to scale up workloads using Airflow: Celery Executor, Kubernetes Pod Operator, and AWS Batch Operator.
We have learned that the Celery Executor is suitable for short and moderately complex tasks, the Kubernetes Pod Operator enhances speed and reliability, and the AWS Batch Operator provides a cost-effective and scalable solution by offloading workloads to the cloud.
In the end, we suggested an approach to maximize the AWS Batch with a dynamic task approach using an AWS S3 bucket and tasks.txt file. Overall, these approaches enhance performance and reduce costs in your cloud environment.