As we explored options for migrating our Kafka clusters from Confluent to MSK, we discovered two potential solutions: MirrorMaker and Kafka Connect Replicator.
Considering our clusters’ substantial number of topics, we opted to start with Kafka Replicator due to its advanced features, including data filtering, transformation, and compatibility options. The choice between these solutions depends on the specific requirements, control, and flexibility needed for data replication tasks.
In this blog, we will provide a comprehensive guide on how we built a straightforward replicator service that efficiently transfers topics from Confluent to MSK. We will outline the necessary steps to ensure a clear understanding of the process and delve into each step, highlighting the key actions required at each stage.

In our setup, we will cover the following steps:
- Cloning our pre-built replicator repository
- Building a Docker image with Amazon MSK Library
- Customizing the connector’s properties
- Kubernetes deployment
- Helm deployment
- Observing the topics in MSK
Cloning the replicator repository
The replicator, which is a part of Confluent Platform built on Kafka Connect, enables seamless data replication between two distinct Kafka clusters. Consequently, we will clone our project, along with its deployment configuration.
git clone git@github.com:naturalett/replicator-connector-confluent-to-msk.git
cd replicator-connector-confluent-to-msk
Building a Docker Image with Amazon MSK Library
In our approach, we build a Docker image by starting with the confluentinc/cp-enterprise-replicator-executable base image and incorporating the Amazon MSK Library. By utilizing the MSK Library, JVM-based Apache Kafka clients gain the ability to leverage AWS IAM for authentication and authorization when interacting with Amazon MSK clusters that have AWS IAM enabled as their authentication mechanism.
You have the option to either build the image yourself or utilize the pre-built image provided below.
cat <<EOF | docker build -t naturalett/cp-enterprise-replicator-executable:7.4.0 . -f -
FROM confluentinc/cp-enterprise-replicator-executable:7.4.0
USER root
RUN curl -sSL https://github.com/aws/aws-msk-iam-auth/releases/download/v1.1.6/aws-msk-iam-auth-1.1.6-all.jar -o /usr/share/java/kafka/aws-msk-iam-auth-1.1.6-all.jar
USER appuser
EXPOSE 8083
CMD ["/etc/confluent/docker/run"]
EOF
Our pre-built image is: naturalett/cp-enterprise-replicator-executable:7.4.0
Customizing the connector’s properties
In the replicator setup, there are three config files:
- Consumer
- Producer
- Replication
This content provides the minimal configuration changes for each file. To configure the properties, you will need to set up specific environment variables, which will then be used to create the corresponding properties.
The necessary environment variables for MSK configuration include your:
- Topic name
- MSK broker endpoint
- MSK cluster name
Additionally, for Confluent Kafka configuration, you will need to set the environment variables for:
- Bootstrap servers
- Bootstrap username
- Bootstrap password
Let’s export the following environment variables:
# Specify the desired replication topic
export TOPIC=<FILL IT UP>
# Specify the desired MSK broker endpoints
export MSK_BROKER_ENDPOINT_1=<FILL IT UP>
export MSK_BROKER_ENDPOINT_2=<FILL IT UP>
export MSK_BROKER_ENDPOINT_3=<FILL IT UP>
# Specify the desired MSK cluster name
export MSK_CLUSTER_NAME=<FILL IT UP>
# Specify the current bootstrap server
export BOOTSTRAP_SERVERS=<FILL IT UP>
# Specify the username and password (API Key) of the bootstrap server
export BOOTSTRAP_USERNAME=<FILL IT UP>
export BOOTSTRAP_PASSWORD=<FILL IT UP>
Generate the replication.properties:
cat replicator/secrets-tpl/replication.properties.tpl | sed -e "s/TOPIC/${TOPIC}/" > replicator/secrets/replication.properties
cat replicator/secrets-tpl/replication.properties.tpl | sed -e "s/TOPIC/${TOPIC}/" > helm/replicator-conf/replication.properties
Generate the producer.properties:
cat replicator/secrets-tpl/producer.properties.tpl | sed -e "s/MSK_BROKER_ENDPOINT_1/${MSK_BROKER_ENDPOINT_1}/" -e "s/MSK_BROKER_ENDPOINT_2/${MSK_BROKER_ENDPOINT_2}/" -e "s/MSK_BROKER_ENDPOINT_3/${MSK_BROKER_ENDPOINT_3}/" -e "s/MSK_CLUSTER_NAME/${MSK_CLUSTER_NAME}/" > replicator/secrets/producer.properties
cat replicator/secrets-tpl/producer.properties.tpl | sed -e "s/MSK_BROKER_ENDPOINT_1/${MSK_BROKER_ENDPOINT_1}/" -e "s/MSK_BROKER_ENDPOINT_2/${MSK_BROKER_ENDPOINT_2}/" -e "s/MSK_BROKER_ENDPOINT_3/${MSK_BROKER_ENDPOINT_3}/" -e "s/MSK_CLUSTER_NAME/${MSK_CLUSTER_NAME}/" > helm/replicator-conf/producer.properties
Generate the consumer.properties:
cat replicator/secrets-tpl/consumer.properties.tpl | sed -e "s/BOOTSTRAP_SERVERS/${BOOTSTRAP_SERVERS}/" -e "s/BOOTSTRAP_USERNAME/${BOOTSTRAP_USERNAME}/" -e "s/BOOTSTRAP_PASSWORD/${BOOTSTRAP_PASSWORD}/" > replicator/secrets/consumer.properties
cat replicator/secrets-tpl/consumer.properties.tpl | sed -e "s/BOOTSTRAP_SERVERS/${BOOTSTRAP_SERVERS}/" -e "s/BOOTSTRAP_USERNAME/${BOOTSTRAP_USERNAME}/" -e "s/BOOTSTRAP_PASSWORD/${BOOTSTRAP_PASSWORD}/" > helm/replicator-conf/consumer.properties
Kubernetes deployment
One option is to generate the properties as mentioned earlier and utilize them to create a Kubernetes deployment.
Create the configuration secrets:
kubectl create secret generic replicator-secret-props-${TOPIC} --from-file=replicator/secrets/ --namespace default
Create the kubernetes deployment:
kubectl apply -f container/replicator-deployment.yaml
cat <<EOF | kubectl create -f -
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: repl-exec-connect-cluster-${TOPIC}
namespace: default
spec:
replicas: 1
template:
metadata:
labels:
app: replicator-app
spec:
containers:
- name: confluent-replicator
imagePullPolicy: IfNotPresent
image: naturalett/cp-enterprise-replicator-executable:7.4.0
resources:
limits:
cpu: "2"
memory: 5Gi
requests:
cpu: "2"
memory: 5Gi
env:
- name: CLUSTER_ID
value: "replicator-k8s"
- name: CLUSTER_THREADS
value: "1"
- name: CONNECT_GROUP_ID
value: "containerized-repl"
- name: KAFKA_HEAP_OPTS
value: "-Xms2048M -Xmx4096M"
- name: KAFKA_OPTS
value: "-Djava.security.auth.login.config=/etc/replicator-config/jaas.conf"
# Note: This is to avoid _overlay errors_ . You could use /etc/replicator/ here instead.
- name: REPLICATION_CONFIG
value: "/etc/replicator-config/replication.properties"
- name: PRODUCER_CONFIG
value: "/etc/replicator-config/producer.properties"
- name: CONSUMER_CONFIG
value: "/etc/replicator-config/consumer.properties"
volumeMounts:
- name: replicator-properties
mountPath: /etc/replicator-config/
volumes:
- name: replicator-properties
secret:
secretName: "replicator-secret-props-${TOPIC}"
defaultMode: 0666
EOF
Verify the replicated topic in your MSK cluster.
Helm deployment
The second option is to generate the properties as mentioned earlier and utilize them to create a Helm deployment.
Install the Helm chart:
helm upgrade -i cp-enterprise-replicator-executable --namespace=default -f helm/values.yaml ./helm
We can use port forward in order to check our connector:
kubectl port-forward -n default svc/cp-enterprise-replicator-executable 8083:8083
Once the port forwarding is executed, you will be able to see:
- Service is up — http://localhost:8083
- Connectors — http://localhost:8083/connectors
- Connector configuration — http://localhost:8083/connectors/replicator/config
- Connector status — http://localhost:8083/connectors/replicator/status
Verify the replicated topic in your MSK cluster.
Monitor Apache Kafka Cluster — Using Kadeck
Once the replicator has been set up in our infrastructure, we can ensure that topics between Confluent and MSK are synchronized. To validate this synchronization, we will leverage Kadeck, which allows us to conveniently manage and monitor our Kafka resources. With Kadeck, we can observe the events in real-time.
Install the Helm chart:
helm upgrade -i my-kadeck-web kadeck/kadeck-web --set image.repository=xeotek/kadeckweb --set image.tag=4.2.9 --namespace=default --version 0.5.0
Add a connection:
Fill the following:
- Connection name: msk-demo
- Bootstrap Servers: <MSK ENDPOINT>:9098
- Security Protocol: SASL_SSL
- Sasl Jaas Config (optional): software.amazon.msk.auth.iam.IAMLoginModule required;
- Sasl Mechanism (optional): aws_msk_iam
After adding the connection, you will be able to observe the newly created topic generated by the replicator, which is based on the earlier added replication configuration.
To validate our setup, we connected to our Confluent Kafka and generated a new message in our test-topic:
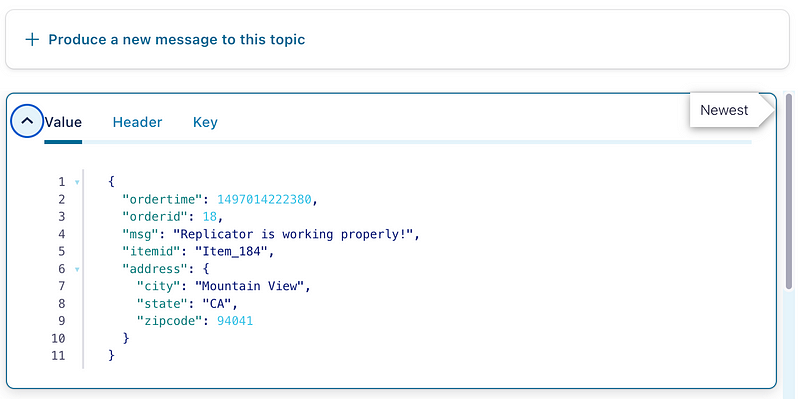
And we can now see it in MSK as well:
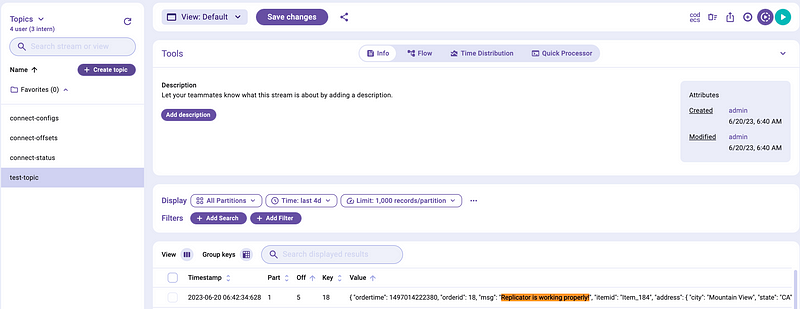
Summarize
This article provides a comprehensive guide on migrating topics from Confluent Kafka to MSK, utilizing the powerful features of Kafka Connect Replicator. Users benefit from advanced capabilities like data filtering, transformation, and compatibility options. Additionally, the article suggests using Kadeck for monitoring Kafka cluster events. To validate the setup, the article demonstrates the process of connecting to Confluent Kafka, generating a new message in a test-topic, and confirming its presence in MSK.
Subscribe to DDIntel Here.
Visit our website here: https://www.datadriveninvestor.com
Join our network here: https://datadriveninvestor.com/collaborate