by Lior Schachter & Lidor Ettinger
The challenges involved in operationalizing machine learning models are one of the main reasons why many machine learning projects never make it to production. The process involves automating and orchestrating multiple steps which run on heterogeneous infrastructure — different compute environments, data processing platforms, ML frameworks, notebooks, containers and monitoring tools.
One popular orchestration tool for managing data and machine-learning workflows is Apache Airflow. Airflow is an Open Source platform created by the community to programmatically author, schedule, and monitor workflows (Airflow is licensed under the Apache Version 2.0). With Airflow you can manage workflows as scripts, monitor them via the user interface (UI), and extend their functionality through a set of powerful plugins.
Apache Liminal (Incubating) uses Domain-Specific-Language (DSL) and provides declarative building blocks that define the workflow, orchestrate the underlying infrastructure and take care of non-functional concerns. Apache Liminal is an Open-Source project which leverages Apache Airflow and other existing libraries and frameworks to express the workflows using the right abstractions; from model training to real time inference in production.
At Natural Intelligence we use ML models to drive personalization and optimization in our comparison marketplaces (e.g. www.top10.com, www.bestmoney.com) and with Apache Liminal we are able to orchestrate the training and deployment of more than 100 ML models on a daily basis.
In this post we introduce how Apache Liminal can simplify the creation and execution of ML workflows using the Amazon Managed Workflows for Apache Airflow (MWAA) a managed orchestration service for Apache Airflow.
Architecture Overview
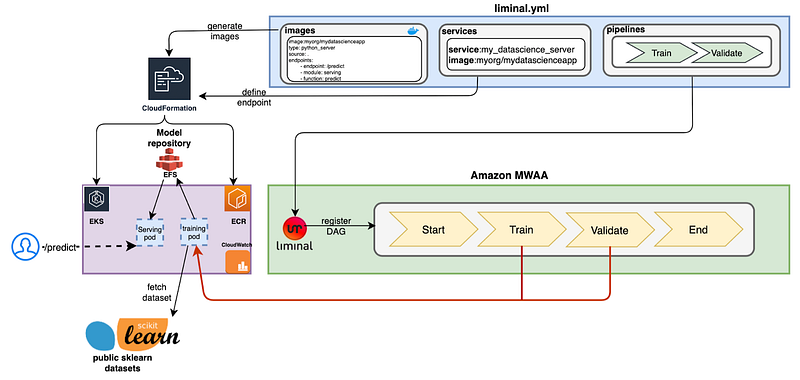
The diagram below exhibits the high-level architecture of the solution. The Liminal .yml definition which corresponds to this flow comprises of 3 sections:
- Pipelines — a pipeline consists of a set of tasks that run sequentially and triggered according to a schedule definition. In ML workflows tasks can be related to feature engineering (Fetch, Clean, Prepare) and to model Training & Validation. This definition is consumed by the Airflow’s Liminal extension and executed as a standard Airflow workflow.
- Services — In the services section we define the online applications which will use the ML model to evaluate a request (Infer). For example, a service of type python_server allows users to serve functions from their code as a constantly running HTTP server responding to incoming requests.
- Images — define the Docker images used by the Pipelines’ steps or by the Services.
Example Overview
Let’s take a walk through a simple Liminal ML workflow, based on the classic Iris dataset classification example. In this example we will define the following steps and services:
- Train, Validate & Deploy — Training and validation execution is managed by Liminal Airflow extension and implemented as Python tasks on Amazon Elastic Kubernetes Service (Amazon EKS). The training task trains a regression model using a public dataset. We then validate the model and deploy it to a model-store in Amazon Elastic File System (Amazon EFS). The liminal.yml snippet:
pipelines:
- pipeline: my_datascience_pipeline
…
schedule: 0 * 1 * * //trigger definition
- tasks:
task: train
type: python
description: train model
image: myorg/mydatascienceapp
cmd: python -u training.py train
...
task: validate
type: python
description: validate the model and deploy
image: myorg/mydatascienceapp
cmd: python -u training.py validate
...
In a fully-scaled production environment, the data fetching, feature engineering as well as the deploy step will be possibly defined as a separate steps in the liminal.yml file and will use distributed processing engines such as Apache Spark or AWS Glue.
- Infer — online inference is done using a Python Flask service running on Amazon EKS. The service exposes the /predict endpoint. It reads the model stored in Amazon EFS and uses it to evaluate the request. The liminal.yml snippet:
services:
- service: my_datascience_server
image: myorg/mydatascienceapp
Solution Walkthrough
In this section we describe the technical details and flow of the solution — from setting up the environment to running online inference on the iris classification example. We have created 1 click installation and provisioning using CloudFormation template, to make this complex phase a no-brainer. You might skip this section and go directly to Running the Example paragraph.
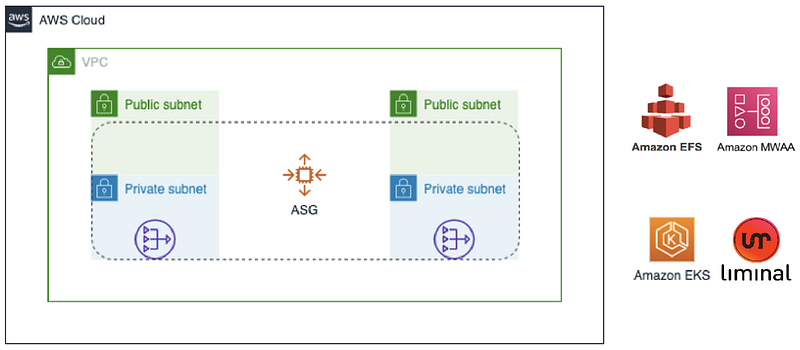
Step 1 — Amazon EKS Setup
The Amazon EKS EC2 node group is deployed into two private subnets in a VPC, and we have a NAT gateway in the private subnets. The running model in Amazon MWAA is configured to launch pods into the same private subnets. An AWS EC2 host instance pre-configured with relevant tools is launched into one of the private subnets to help you configure the Amazon EKS cluster post the CloudFormation deployment.
Step 2 — Setup Amazon EFS
We use Amazon EFS provisioner to enable using Amazon EFS as a model store. The Liminal pipeline is using a kubernetesPodOperator in order to mount the volume and to store the trained model. Amazon EFS file system can be accessed from multiple availability zones and it is valuable for multi-AZ clusters, therefore the Liminal pipeline can mount the volume from any of the available AZs that exist in the cluster.
Step 3 — Setup Working Environment
In this step we build the working environment on an EC2 instance. We install AWS Command Line Interface (AWS CLI), kubectl, and eksctl in one of the two private subnets. This can only be accessed through Session Manager in AWS System Manager. The EC2 instance also has scripts available to configure the kubectl client, Amazon EFS, the liminal project and setting up the Amazon MWAA roles.
Step 4 — Amazon MWAA setup
The main stack creates an Amazon S3 bucket to store the yaml files and the prerequisites of the cluster for the Amazon MWAA environment.

The S3 bucket contains the following resources:
- requirements.txt — We Install Python dependencies by adding a requirements.txt file to the Airflow S3 bucket. The requirements.txt file contains the apache-liminal pip package which gets installed during the startup of the Airflow components.
- dags:
▹ kube_config.yaml — a Cluster context which configures access to the Amazon EKS cluster by using a configuration file.
▹ liminal_dags.py — Python module for parsing liminal.yml files and registering pipelines as Airflow DAGs.
▹ pipelines — a folder structure of declared machine learning pipelines models.
Amazon MWAA environment class contains the following configuration:
# Liminal’ home folder containing the yaml files
"core.liminal_home": "/usr/local/airflow/dags",
# Kubernetes cluster context configuration.
"kubernetes.cluster_context": "aws",
# The kubeconfig file that configures access to a cluster.
"kubernetes.config_file": "/usr/local/airflow/dags/kube_config.yaml",
# The namespace to run within kubernetes.
"kubernetes.namespace": "default"
Running the Example
To get started, you need to have an AWS account with administrator privileges. If you don’t have one, sign up for one before completing the following steps:
Create the stack
- Sign in to the AWS Management Console as an AWS Identity and Access Management (IAM) power user, preferably an admin user
- Choose Launch Stack
- You can specify your choice of Amazon EKS cluster name, Amazon EKS node instance type, and Amazon MWAA environment name, or use the default values
- Choose Create Stack

The stack takes about 35 minutes to complete.
Setup Apache Liminal
- Navigate to the Systems Manager console, choose Session Manager in the navigation pane.
- Choose Start session.
- Select the EC2 host instance named <stack name>-xxxx-PrepStack-xxxx-jumphost.
- Choose Start session.
- Export the AWS_SECRET_ACCESS_KEY and AWS_ACCESS_KEY_ID environment variables for the user that deployed the CloudFormation stack. If needed, export the AWS_SESSION_TOKEN as well.
A terminal of the host instance opens up.
For more information, see Environment variables to configure the AWS CLI.
Environment setup
At the prompt, enter the following command to configure the Kubernetes client (kubectl) and to setup the environment:
sh /tmp/liminal-startup/env_setup.sh
The following diagram illustrates the environment setup:
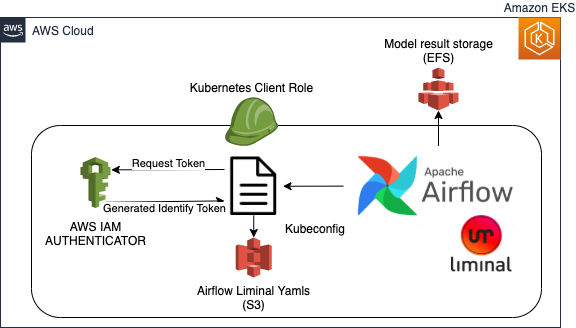
The env setup includes:
- up an access between Airflow and Amazon EKS
- Defining Amazon EFS
Liminal Build and Deploy
Enter the following command:
sh /tmp/liminal-startup/liminal_setup.sh
The command will:
- Clone & customize liminal.yaml to the cloud environment specific parameters.
- Run liminal build which will create a docker image of the Iris Classification.
- Push docker image to Amazon ECR after authentication.
- Deploy files to Amazon S3 — liminal.yaml & the liminal_dags.py.
Execute the Pipeline
Once we have built and deployed the artifacts, we can run the Airflow DAG.
- Navigate to the and open the Open Airflow UI.
- Run the my_datascience_pipeline
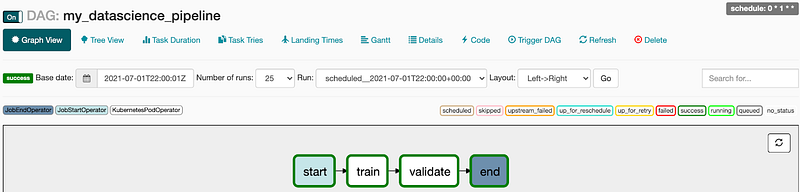
Liminal plugin will use the definition in the yaml to execute the pipeline as standard Airflow DAG. The result will be stored in Amazon EFS.
Launch a Python Flask server
After executing the pipeline defined in the yaml file the model is stored in Amazon EFS. We will launch a docker container that is mounted to the Amazon EFS, where the result of the trained model exists.
sh /tmp/liminal-startup/model_server.sh
Our pre-built docker image in Amazon ECR contains a serving Python class in Flask which we will use in order to check the healthcheck of the microservice and to get the prediction that was stored in Amazon EFS.
Getting model prediction
After running the above script of the model_server.sh you will locally get a Python flask server in a container.
- Check that the Python flask server is up:
curl localhost/healthcheck
- Check the prediction:
curl -X POST -d '{"petal_width": "2.1"}' localhost/predict
Cleaning up the environment
- Open the AWS CloudFormation console at https://console.aws.amazon.com/cloudformation.
- On the Stacks page in the CloudFormation console, select the stack that you want to delete. The stack must be currently running.
- In the stack details pane, choose Delete (select ‘Delete’ stack when prompted).
Setup your local Apache-Liminal Environment
You might want to get started in local environment. A guide to install and run the Iris Classification locally is described here.
Join The Effort!
In this blog post we introduced how Apache Liminal can be used together with Amazon MWAA to simplify the orchestration of ML workflows. We have exemplified using a simple ML workflow how data scientists can use those tools to independently author and execute their ML application in AWS cloud.
Liminal is an Open-Source project working under the Apache incubator and according to the Apache way. As such, we are very open to contributions and want to grow a robust community to achieve greatness together. Join us in GitHub at https://github.com/apache/incubator-liminal and report or Implement issues and features on https://issues.apache.org/jira/projects/LIMINAL