As organizations increasingly embrace the data mesh paradigm, similar to the way Airflow is leveraged for orchestrating ETL flows and ML tasks, OpenMetadata proves to be an invaluable tool for simplifying the complexities involved in metadata management.
While Airflow empowers us to handle large-scale data processing, OpenMetadata addresses the challenges that arise from the vast amount of metadata generated in our pipelines.

There are several ways in which we can benefit from OpenMetadata:
- Data visibility — Gain insights into your data, including its structure, relationships, and context.
- Data quality — Implement data cleaning procedures.
- Real-time updates — Stay informed about the latest data.
- Data ownership — Identify data maintainers.
- Storage transparency — Understand where your data is stored.
Gain a better understanding of the advantages
To delve deeper into the benefits of OpenMetadata, we will:
- Deploy OpenMetadata in our cluster
- Integrate OpenMetadata with one of our Data services, such as Airflow.
- Deploy an Iris Classification and establish its connection to the lineage.
- Improve your Data Flow Visibility
Prerequisites:
- Local Kubernetes for Mac
- Helm
- kubectl
Deploying OpenMetadata
To start, set up a Kubernetes cluster on your local machine. This can be done using tools like Minikube or by enabling Kubernetes within Docker Desktop.
Let’s explore how we configure it with Helm chart
You can either follow the instructions provided here or execute the following commands:
kubectl create secret generic mysql-secrets --from-literal=openmetadata-mysql-password=openmetadata_password
kubectl create secret generic airflow-secrets --from-literal=openmetadata-airflow-password=admin
helm repo add open-metadata https://helm.open-metadata.org/
kubectl create secret generic airflow-mysql-secrets --from-literal=airflow-mysql-password=airflow_pass
helm install openmetadata-dependencies open-metadata/openmetadata-dependencies --version 1.0.3
helm install openmetadata open-metadata/openmetadata --version 1.0.3
To connect to OpenMetadata, let’s utilize the “kubectl port-forward” command:
kubectl -n default port-forward service/openmetadata 8585:8585
Integrating OpenMetadata With Airflow
In our demo, we will be utilizing the pre-existing Airflow dependency that comes bundled with OpenMetadata. Due to resource limitations on our local machine, we will not create a custom Airflow installation.
Airflow plays a crucial role as one of the bundled dependencies in OpenMetadata. In this context, we will upgrade the previously deployed Airflow installation by configuring a set of environment variables. These variables enable OpenMetadata to scan and recognize our Airflow instance as our designated “Production” Airflow.
But first we need to obtain the JWT_TOKEN from OpenMetadata, let’s proceed with the following steps:
- Open the browser in: http://localhost:8585/
Username: admin \ Password: admin - Navigate to Settings -> Bots -> ingestion-bot and copy the JWT_TOKEN
Replace the value of the AIRFLOW__LINEAGE__JWT_TOKEN configuration parameter with the corresponding JWT_TOKEN that you obtained above:
cat << EOF >> values.yaml
# you can find more details about this here https://github.com/airflow-helm/charts
airflow:
enabled: true
airflow:
image:
repository: docker.getcollate.io/openmetadata/ingestion
tag: 1.0.0
pullPolicy: "IfNotPresent"
executor: "KubernetesExecutor"
config:
AIRFLOW__LINEAGE__BACKEND: "airflow_provider_openmetadata.lineage.backend.OpenMetadataLineageBackend"
AIRFLOW__LINEAGE__AIRFLOW_SERVICE_NAME: "local_airflow"
AIRFLOW__LINEAGE__OPENMETADATA_API_ENDPOINT: "http://openmetadata.default.svc.cluster.local:8585/api"
AIRFLOW__LINEAGE__AUTH_PROVIDER_TYPE: "openmetadata"
AIRFLOW__LINEAGE__JWT_TOKEN: "<JWT_TOKEN>"
EOF
helm upgrade -i openmetadata-dependencies -f values.yaml open-metadata/openmetadata-dependencies --version 1.0.3
To connect to Airflow, let’s execute the “kubectl port-forward” command:
kubectl -n default port-forward service/openmetadata-dependencies-web 8080:8080
Deploying an Iris Classification
After setting up our environment, we can move forward with deploying our DAG. We will begin with training a model using the Iris dataset, followed by executing the trained model to make predictions about species. Furthermore, we will define inlets and outlets within our tasks to establish the data flow and task dependencies in our pipeline.
Our goal is to predict the species of an Iris flower based on its four attributes: sepal length, sepal width, petal length, and petal width.
In this scenario, the classification task involves training a machine learning model, specifically a Decision Tree Classifier.
First, we will download the DAG:
curl -sSL https://gist.githubusercontent.com/naturalett/1fb33e337d3b664b0f8431613b2d5dea/raw/b618053ed2e8cc1fe8b582f3270943ed33f00934/iris_classification.py >> iris_classification.py
In the provided code, we randomly select a flower and make predictions using our model:
# Use the loaded model for inference or further processing
species_names = ['setosa', 'versicolor', 'virginica']
# Generate a random input for each species
for species in species_names:
sepal_length = random.uniform(4.0, 8.0)
sepal_width = random.uniform(2.0, 4.5)
petal_length = random.uniform(1.0, 7.0)
petal_width = random.uniform(0.1, 2.5)
X_new = np.array([[sepal_length, sepal_width, petal_length, petal_width]]) # Input for prediction
prediction = loaded_model.predict(X_new)
The X_new array represents the attribute values of an Iris flower that we want to classify.
Next, we will deploy the DAG to Airflow:
POD_NAME=$(kubectl get pod -n default -l 'component=web' -o jsonpath='{.items[0].metadata.name}')
kubectl cp iris_classification.py default/$POD_NAME:/opt/airflow/dags/
Let’s give it a push and refresh the DAGs in Airflow to ensure the latest updates are applied:
kubectl exec -n default $POD_NAME -- python -c "from airflow.models import DagBag; d = DagBag();"
Access Airflow on your localhost through the previously applied port-forwarding and trigger the iris_classification DAG. After that, check the logs of the train_and_export task to observe the inlets and outlets populated by the task:
[2023-05-30, 06:51:30 UTC] {lineage_parser.py:126} INFO - Found _inlets {'tables': ['mysql.my_database.my_database.models']} in task train_and_export
[2023-05-30, 06:51:30 UTC] {lineage_parser.py:126} INFO - Found _outlets {'tables': ['mysql.my_database.openmetadata_db.classification']} in task train_and_export
Subsequently, examine the logs of the load_model task to discover the model’s prediction based on the input specified in the DAG:
[2023-05-30, 06:51:53 UTC] {logging_mixin.py:115} INFO - Species: setosa
[2023-05-30, 06:51:53 UTC] {logging_mixin.py:115} INFO - Prediction: [1]
[2023-05-30, 06:51:53 UTC] {logging_mixin.py:115} INFO - Image Link: https://en.wikipedia.org/wiki/Iris_setosa
[2023-05-30, 06:51:53 UTC] {logging_mixin.py:115} INFO - Species: versicolor
[2023-05-30, 06:51:53 UTC] {logging_mixin.py:115} INFO - Prediction: [1]
[2023-05-30, 06:51:53 UTC] {logging_mixin.py:115} INFO - Image Link: https://en.wikipedia.org/wiki/Iris_versicolor
[2023-05-30, 06:51:53 UTC] {logging_mixin.py:115} INFO - Species: virginica
[2023-05-30, 06:51:53 UTC] {logging_mixin.py:115} INFO - Prediction: [0]
[2023-05-30, 06:51:53 UTC] {logging_mixin.py:115} INFO - Image Link: https://en.wikipedia.org/wiki/Iris_virginica
Improve Your Data Flow Visibility
inlets and outlets make the data flow within your pipeline more explicit and visible. By inspecting the inlets and outlets of a task, developers and data engineers can quickly understand the data dependencies of each task, allowing them to better debug and troubleshoot the overall workflow.
Let’s access to OpenMetadata on the localhost through the previously applied port-forwarding. (Username: admin \ Password: admin)
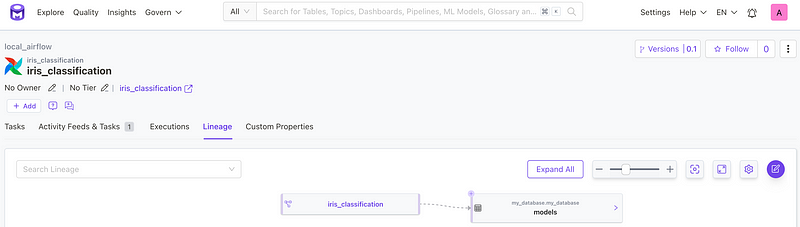
Tracking data in this manner holds significant value for auditing, compliance, and data governance objectives. It enables you to trace the data’s origin and its transformation history through the pipeline.
In our use case of the train_and_export task, the inlets and outlets are pointing to the location of our model in the MySQL, as shown in the screenshot above and demonstrated in the code snippet below:
with dag:
train_export_operator = PythonOperator(
task_id='train_and_export',
python_callable=train_and_export_model,
outlets={
"tables": ["mysql.my_database.my_database.models"]
},
inlets={
"tables": ["mysql.my_database.my_database.models"]
}
)
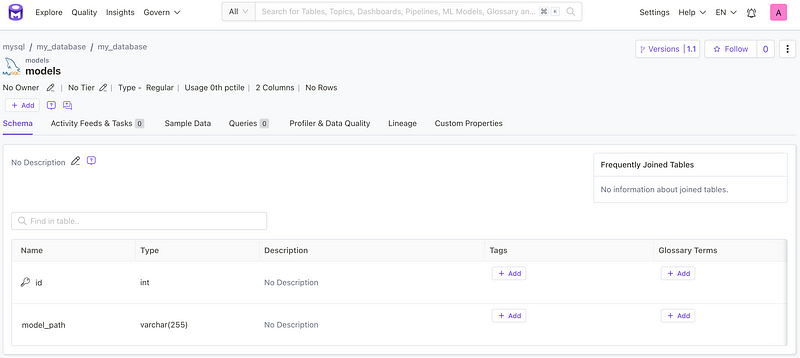
In addition to the relationship between the DAG and the associated database, we can also check the attributes of the database that were created while we triggered the DAG:
Summarize
In this article, we explore OpenMetadata and Airflow as a Data Mesh paradigm. OpenMetadata simplifies metadata management, while Airflow handles large-scale data processing. We provided a deployment instructions for OpenMetadata, including integration with Airflow. Additionally, we have included an Iris Classification DAG that runs in Airflow and can be visualized in OpenMetadata. As well, we highlighted the importance of tracking data and its implications through inlets and outlets.
What we will do next…
We will explore the integration of OpenMetadata in our production environment, establishing connections with various tools such as Athena, Redshift, Glue, MySQL, and Airflow.