At Natural Intelligence we are running a Kubernetes cluster on AWS which makes it is easy to deploy, manage and scale containerized applications. With cloud native becoming the de-facto standard for building and deploying modern applications, and with the proliferation of microservices style application architectures, agile DevOps processes and continuous delivery workflows, there has been an emerging need for highly scaled cloud native business automation platforms.
Flexible scaling capabilities and robust infrastructure are required to deliver flexible deployments.
Recently, I got the opportunity to engage with development teams to deliver a resilient, manageable, secure and highly available CI/CD process for a microservices architecture using kubernetes.
This post describes an early stage design decisions:
- Creating the microservice simple configuration
- Using a CI/CD pipeline blueprint to set up a microservice
The above design calls for two main things to do:
First, build the configuration of the service that I’m creating. This includes all the external resources the service relies on as: source repository and data endpoints of all the services it consumes.
Second, we take this configuration and run it through a predefined CI/CD blueprint, tailored for this kind of a service.

Creating the microservice simple configuration
A typical microservice has a lot of integration points to the encompassing system. All of these interfaces have to be well defined. For this reason, we chose to write a Python script in order to generate a service config file which later we will use while running the pipeline.
The config file includes the following:
- Database — schema, username and password
- GitHub — template files, permissions
- DockerHub — permissions
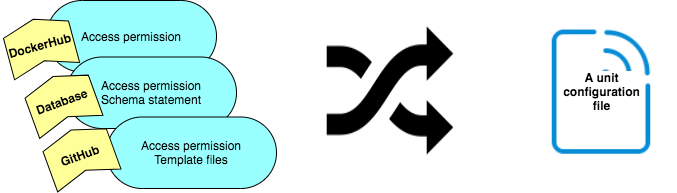
I ask the user about his service configuration and based on a Python template I create the config file that is scoped to an individual microservice. The output of this script is a config file that will be used as an input for the CI/CD pipeline blueprint.
This config file is scoped to an individual microservice, so the teams can have a simple service configuration. That allows us to extend the configuration in a manner that is simple and easy to operate.
The design impact: This service config file makes the pipeline manageable. It dictates a discipline that can be set for other CI/CD processes.
Processing a microservice pipeline blueprint
Before we are able to deploy a microservice to the production environment from the generated config file, we would need to create a pipeline for automating the entire build and deploy process.
From a system architecture perspective, the pipeline consists of five primary stages:
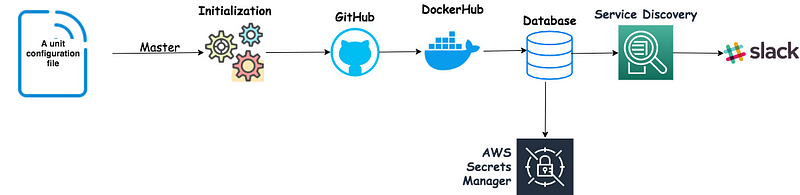
Initialization: Detect and read the config file.
GitHub: Automate creation of repository from template files, for getting the base application framework in place and then setting all the needed permissions for the service (The developer needs to add his code inside of the generated code).
DockerHub: Automate the image creation from the repository we just created.
Database: Automate the creation of schemas, username and password. For that we are generating credentials and store them in SSM with KMS RSA256 encryption. There is another post that describes how we use AWS SSM for centralized secret manager them later.
Service Discovery: Update the core service mechanism with the new service that we just created.
The pipeline described above cover these two aspects:
- Pipeline resource generation — Creating the baseline integration of a microservice
- Pipeline execution — Creating the CI/CD pipeline of a microservice

Pipeline resource generation
From the microservice pipeline blueprint, we generate the full deployment pipeline for the microservice including the resources needed by it as defined in the configuration file.
The key idea is that the config map identifies the needed resources by the microservice. Then those identified resources can be instantiated as fully independent for the microservice.
We recommend you using the Custom GitHub Checks With Jenkins Pipeline in the stages in order to reflect the build status on the pull request in GitHub.
Pipeline execution
After the deployment pipeline creation succeeded and the baseline integration of a microservice was created. Now you can trigger the microservice CI/CD pipeline on the cluster.
This pipeline can have the following steps:

Once this pipeline was created then you can update and configure it in the same way as any other pipeline you created. Now, we can go ahead and start working on the microservice functionality.
The design impact: Integration resources might be implemented on top of different technology stacks.
Summary
As we have covered in this post we are trying to allow easy and manageable way to deploy a microservice. For that we have created a deployment pipeline blueprint and we encountered two key design factors in a journey to a production ready mechanism:
- A service config file makes the pipeline manageable.
- Integration resources might be implemented on top of different technology stacks.
Originally published at https://www.naturalint.com on September 24, 2020.