Developing and releasing new software versions is an ongoing process that demands careful attention to detail. It’s essential to have the ability to track and analyze the entire process, even retrospectively, to identify any issues and take corrective measures.
This is where the concept of continuous integration comes into the picture.
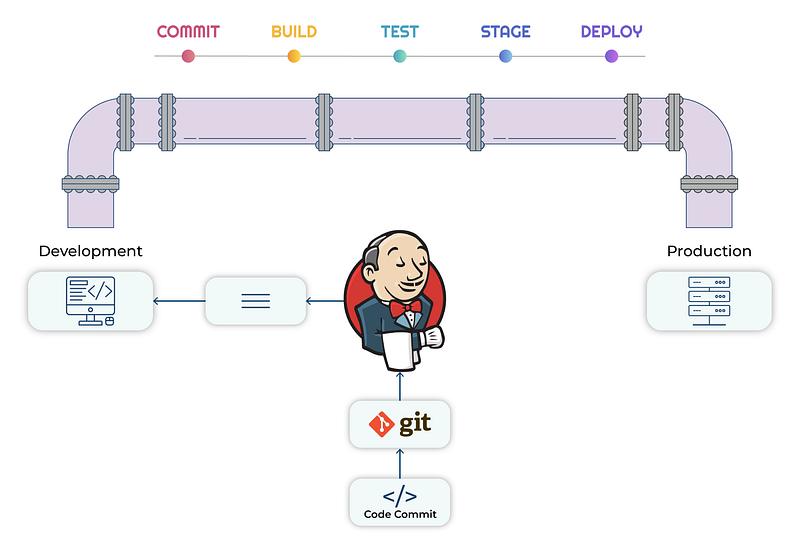
By adopting a continuous integration approach, we can effectively monitor the various stages of the software development process and analyze the results. This helps us to identify any potential issues, analyze them, and make the necessary adjustments to improve the overall development process.
In this blog post, we will explore the concept of continuous integration and its benefits. We will discuss how to achieve continuous integration using Jenkins and provide insights on how this approach can help you streamline your software development process.
Want to make practice training about Continuous Integration and Jenkins?
You are invited to take a look at the course I’ve created, where you will write a complete pipeline in AWS based on SDLC principles, with my guidance.
Continuous Integration and Jenkins Pipelines in AWS
What triggers continuous integration from the perspective of the development team?
The development team triggers continuous integration by pushing code changes to the code repository. This action triggers an automated pipeline that builds, tests, and deploys the updated software version.
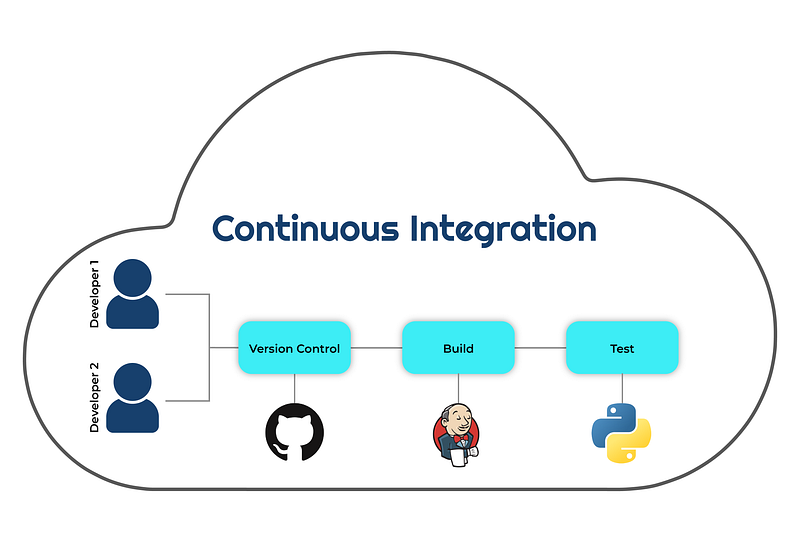
The concept of a structured workflow is to establish a standardized order of operations that developers agree upon, enabling them to ensure that their subsequent versions are built in accordance with the software development life cycle (SDLC) defined by management. Let’s now examine some of the primary advantages of continuous integration:
- Version history — Developers can easily track their production versions and compare the performance of different versions during development. In addition, they can quickly rollback to a previous version in case of any production issues.
- Quality testing — Developers can test their versions on a staging environment to demonstrate how the new version performs in an environment similar to production. Instead of running the version on their local machine, which may not be comparable to the real environment, they can define a set of tests, such as unit tests, integration tests, and more, that will take their new version through a predefined workflow. This testing process will serve as their signature and ensure that the new version is safe to be deployed in a production environment.
- Schedule triggering — Developers no longer need to manually trigger their pipeline or define a new pipeline for each new project. As a DevOps team, it is our responsibility to create a robust system that will attach to each project its own pipeline. Whether it’s a common pipeline with slight changes to match the project or the same pipeline, developers can focus on writing code while the continuous integration takes care of the rest. Scheduling an automatic triggering, for example, every morning or evening, will ensure that the current code in Github is always ready for release.
Jenkins in the Age of Continuous Integration
To achieve the desired pipeline workflow, we’ll deploy Jenkins and create a comprehensive pipeline that prioritizes version control, automated testing, and triggers.
Prerequisites:
- A virtual machine with a docker engine
Containerize Jenkins
We will deploy Jenkins in a Docker container in order to simplify the deployment of our CI/CD pipelines.
Let’s deploy Jenkins:
docker run -d \
--name jenkins -p 8080:8080 -u root -p 50000:50000 \
-v /var/run/docker.sock:/var/run/docker.sock \
naturalett/jenkins:2.387-jdk11-hello-world
Validate the Jenkins Container:
docker ps | grep -i jenkins
Retrieve the Jenkins initial password:
docker exec jenkins bash -c -- 'cat /var/jenkins_home/secrets/initialAdminPassword'
Connect to Jenkins on the localhost
If you’re looking for assistance with setting up Jenkins in a Docker container, I encourage you to visit my YouTube channel, where you’ll find detailed tutorials and valuable insights. Feel free to subscribe for regular updates:
Building a Continuous Integration Pipeline
I chose to use Groovy in Jenkins pipelines because it offers a number of benefits:
- Groovy is a scripting language that is easy to learn and use
- Groovy offers features for writing concise, readable, and maintainable code
- Groovy’s syntax is similar to Java, making it easier for Java developers to adopt
- Groovy has excellent support for working with data formats commonly used in software development
- Groovy provides an efficient and effective way to build robust and flexible CI/CD pipelines in Jenkins
Our Pipeline Consists of Four Phases:
Phase 1 — The Agent
To ensure the code is built as expected with no incompatible dependencies, each pipeline requires a virtual environment. We create an agent (virtual environment) in a Docker container during the following phase. Since Jenkins is also running in a Docker container, we’ll mount the Docker socket to enable agent execution.
pipeline {
agent {
docker {
image 'docker:19.03.12'
args '-v /var/run/docker.sock:/var/run/docker.sock'
}
}
...
...
...
}
Phase 2— The History of Versions
Versioning is an essential practice that allows developers to track changes to their code and compare software performance, enabling them to make informed decisions on whether to roll back to a previous version or release a new one. In the next phase, we create a Docker image from our code and assign it a tag based on our predetermined set of definitions.
For example: Date — Jenkins Build Number — Commit Hash
pipeline {
agent {
...
}
stages {
stage('Build') {
steps {
script {
def currentDate = new java.text.SimpleDateFormat("MM-dd-yyyy").format(new Date())
def shortCommit = sh(returnStdout: true, script: "git log -n 1 --pretty=format:'%h'").trim()
customImage = docker.build("naturalett/hello-world:${currentDate}-${env.BUILD_ID}-${shortCommit}")
}
}
}
}
}
After completing the previous phase, a Docker image of our code was generated and can now be accessed in our local environment.
docker image | grep -i hello-world
Phase 3— The Test
Testing is a critical step to ensure that a new release version meets all functional and requirements tests. In the following stage, we run tests against the Docker image generated in the previous stage, which contains the potential next release.
pipeline {
agent {
...
}
stages {
stage('Test') {
steps {
script {
customImage.inside {
sh """#!/bin/bash
cd /app
pytest test_*.py -v --junitxml='test-results.xml'"""
}
}
}
}
}
}
Phase 4— The Scheduling Trigger
Automating the pipeline trigger allows developers to focus on code writing while ensuring stability and readiness for the next release. To achieve this, we define a morning schedule that triggers the pipeline automatically as the development team starts their day.
pipeline {
agent {
...
}
triggers {
// https://crontab.guru
cron '00 7 * * *'
}
stages {
...
}
}
An end-to-end pipeline of the process
To execute our pipeline, we have included a pre-defined pipeline into Jenkins. Simply initiate the “my-first-pipeline” Jenkins job to begin.
- Agent — is a virtual environment used for the pipeline
- Trigger —is used for automatic scheduling in the pipeline
- Clone stage — is responsible for cloning the project repository
- Build stage — involves creating the Docker image for the project
To access the latest commit and other Git features, we install Git package - Test stage — involves performing tests on our Docker image
pipeline {
agent {
docker {
image 'docker:19.03.12'
args '-v /var/run/docker.sock:/var/run/docker.sock'
}
}
triggers {
// https://crontab.guru
cron '00 7 * * *'
}
stages {
stage('Clone') {
steps {
git branch: 'main', url: 'https://github.com/naturalett/hello-world.git'
}
}
stage('Build') {
steps {
script {
sh 'apk add git'
def currentDate = new java.text.SimpleDateFormat("MM-dd-yyyy").format(new Date())
def shortCommit = sh(returnStdout: true, script: "git log -n 1 --pretty=format:'%h'").trim()
customImage = docker.build("naturalett/hello-world:${currentDate}-${env.BUILD_ID}-${shortCommit}")
}
}
}
stage('Test') {
steps {
script {
customImage.inside {
sh """#!/bin/bash
cd /app
pytest test_*.py -v --junitxml='test-results.xml'"""
}
}
}
}
}
}
Summarize
We’ve gained an understanding of how continuous integration fits into our daily work, as well as some key pipeline workflows, which we’ve tried out firsthand.
If you’re interested in further exploring different pipeline scenarios and learning practical production skills for implementing continuous integration in your own work, check out my course:
Hands-On Mastering DevOps — CI and Jenkins Container Pipelines