Learn about implementing CI using Jenkins, a popular automation tool, and how this approach can optimize and streamline your software development process.
Developing and releasing new software versions is an ongoing process that demands careful attention to detail. The ability to monitor and analyze the entire process is critical for identifying any potential issues and implementing effective corrective measures.
The concept of continuous integration becomes relevant at this point.

By adopting a continuous integration approach, software development teams can carefully monitor each stage of the development process and conduct an in-depth analysis of the outcomes. This facilitates the early detection and diagnosis of potential issues, enabling developers to make necessary adjustments and improve the overall development process. In other words, continuous integration provides a systematic way of identifying problems and continuously enhancing software quality, ultimately leading to a better end product.
The focus of this post is on exploring the benefits of continuous integration in software development. Specifically, we will delve into the practical aspects of implementing continuous integration using Jenkins, a popular automation tool, and share valuable insights on how this approach can help optimize and streamline your software development process. By the end of this post, you will have a better understanding of how continuous integration can improve your workflow and help you build better software more efficiently.
From the Development Team’s Perspective, What Initiates Continuous Integration?
With continuous integration, the development team initiates the process by pushing code changes to the repository, which triggers an automated pipeline to build, test, and deploy the updated software version. This streamlines the development cycle, leading to faster feedback and higher-quality software.
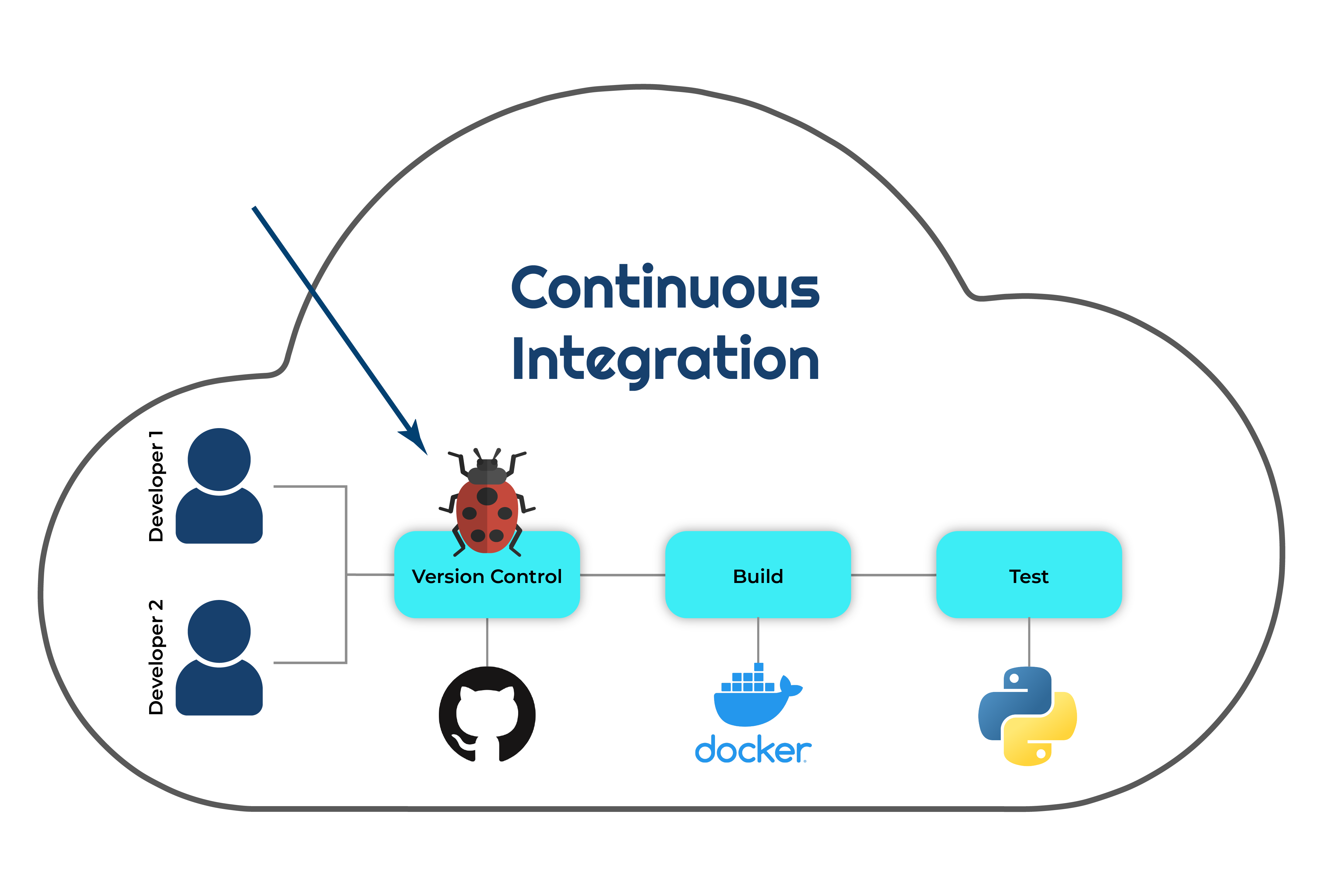
A structured workflow aims to establish a standardized order of operations for developers, ensuring that subsequent versions of the software are built according to the software development life cycle defined by management. Here are some primary benefits of continuous integration:
- Version control – With continuous integration, developers can easily track production versions and compare the performance of different versions during development. In addition, the ability to roll back to a previous version is also available, should any production issues arise.
- Quality assurance – Developers can test their versions on a staging environment, demonstrating how the new version performs in an environment similar to production. Instead of running the version on their local machine, which may not be comparable to the real environment, developers can define a set of tests, including unit tests and integration tests, among others, that will take the new version through a predefined workflow. This testing process serves as their signature, ensuring the new version is safe to be deployed in a production environment.
- Scheduled triggering – Developers no longer need to manually trigger their pipeline or define a new pipeline for each new project. As a DevOps team, it is our responsibility to create a robust system that attaches to each project its own pipeline. Whether it is a common pipeline with slight changes to match the project or the same pipeline, developers can focus on writing code while continuous integration takes care of the rest. Scheduling an automatic triggering (for example, every morning or evening) ensures that the current code in GitHub is always ready for release.
Jenkins in the Era of Continuous Integration
To establish the desired pipeline workflow, we will deploy Jenkins and design a comprehensive pipeline that emphasizes version control, automated testing, and triggers.
Prerequisite
- A virtual machine with a Docker engine
Containerizing Jenkins
To simplify the deployment of our CI/CD pipelines, we will deploy Jenkins in a Docker container.
Deployment of Jenkins:
docker run -d \
--name jenkins -p 8080:8080 -u root -p 50000:50000 \
-v /var/run/docker.sock:/var/run/docker.sock \
naturalett/jenkins:2.387-jdk11-hello-worldValidate the Jenkins container:
docker ps | grep -i jenkinsRetrieve the Jenkins initial password:
docker exec jenkins bash -c -- 'cat /var/jenkins_home/secrets/initialAdminPassword'Connect to Jenkins on the localhost (http://localhost:8080/).
Building a Continuous Integration Pipeline
I chose to utilize Groovy in Jenkins pipelines due to its numerous benefits:
- Groovy is a scripting language that is straightforward to learn and utilize.
- Groovy offers features that enable developers to write code that is concise, readable, and maintainable.
- Groovy’s syntax is similar to Java, making it easier for Java developers to adopt.
- Groovy has excellent support for working with data formats commonly used in software development.
- Groovy provides an efficient and effective way to build robust and flexible CI/CD pipelines in Jenkins.
The Four Phases of Our Pipeline
Phase 1: The Agent
To ensure that our code is built with no incompatible dependencies, each pipeline requires a virtual environment. In the following phase, we create an agent (virtual environment) in a Docker container. As Jenkins is also running in a Docker container, we’ll mount the Docker socket to enable agent execution.
pipeline {
agent {
docker {
image 'docker:19.03.12'
args '-v /var/run/docker.sock:/var/run/docker.sock'
}
}
...
...
...
}Phase 2: The History of Versions
We recognize the importance of versioning in software development, which allows developers to monitor code changes and evaluate software performance to make informed decisions about rolling back to a previous version or releasing a new one. In the subsequent phase, we generate a Docker image from our code and assign it a tag based on our predetermined set of definitions.
For example: Date — Jenkins Build Number — Commit Hash
pipeline {
agent {
...
}
stages {
stage('Build') {
steps {
script {
def currentDate = new java.text.SimpleDateFormat("MM-dd-yyyy").format(new Date())
def shortCommit = sh(returnStdout: true, script: "git log -n 1 --pretty=format:'%h'").trim()
customImage = docker.build("naturalett/hello-world:${currentDate}-${env.BUILD_ID}-${shortCommit}")
}
}
}
}
}Upon completion of the previous phase, a Docker image of our code has been successfully created and is now available for use in our local environment.
docker image | grep -i hello-worldPhase 3: The Test
In order to ensure that a new release version meets all functional and requirements tests, testing is a critical step. In the following stage, we execute tests against the Docker image that was generated in the previous stage and contains the potential next release.
pipeline {
agent {
...
}
stages {
stage('Test') {
steps {
script {
customImage.inside {
sh """#!/bin/bash
cd /app
pytest test_*.py -v --junitxml='test-results.xml'"""
}
}
}
}
}
}Phase 4: The Scheduling Trigger
Automating the pipeline trigger is crucial in allowing developers to concentrate on writing code while ensuring the stability and readiness of the next release. We accomplish this by setting up a morning schedule that automatically triggers the pipeline as the development team begins their workday.
pipeline {
agent {
...
}
triggers {
// https://crontab.guru
cron '00 7 * * *'
}
stages {
...
}
}An End-to-End Pipeline of the Process
The pipeline execution process has been made simple by incorporating a pre-defined pipeline into Jenkins. You can get started by initiating the “my-first-pipeline” Jenkins job.
- The Agent stage creates a virtual environment used for the pipeline.
- The Trigger stage is responsible for automatic scheduling in the pipeline.
- The Clone stage is responsible for cloning the project repository.
- The Build stage involves creating a Docker image for the project. (To access the latest commit and other Git features, we install the Git package.)
- The Test stage involves performing tests on our Docker image.
pipeline {
agent {
docker {
image 'docker:19.03.12'
args '-v /var/run/docker.sock:/var/run/docker.sock'
}
}
triggers {
// https://crontab.guru
cron '00 7 * * *'
}
stages {
stage('Clone') {
steps {
git branch: 'main', url: 'https://github.com/naturalett/hello-world.git'
}
}
stage('Build') {
steps {
script {
sh 'apk add git'
def currentDate = new java.text.SimpleDateFormat("MM-dd-yyyy").format(new Date())
def shortCommit = sh(returnStdout: true, script: "git log -n 1 --pretty=format:'%h'").trim()
customImage = docker.build("naturalett/hello-world:${currentDate}-${env.BUILD_ID}-${shortCommit}")
}
}
}
stage('Test') {
steps {
script {
customImage.inside {
sh """#!/bin/bash
cd /app
pytest test_*.py -v --junitxml='test-results.xml'"""
}
}
}
}
}
}Summary
We have gained a deeper understanding of how Continuous Integration (CI) fits into our daily work and have obtained practical experience with essential pipeline workflows.